
Jie Zhang | Researcher, School of Computer Science, Peking University
— Included in Data Dialogue, Issue 002
Brief Introduction
This article takes a deep dive into GPU–SSD direct access technology, examining both how it has evolved and its value to the industry. It highlights the core limitations of traditional CPU-centric architecture, including I/O requests that are heavily CPU-bound, disjointed software stacks, and high data transfer overhead. In response to these limitations, both academia and the industry have explored optimization strategies, such as pipeline improvement and data and control path modification, setting the stage for GPU–SSD direct access. Following on, the article's focus turns to mainstream BaM technology. BaM allows GPUs to access data on SSDs directly, bypassing the CPU. It introduces a new level of determinism and efficiency in system architecture. Many enterprises and universities have explored supporting innovations, including storage software stacks, tiered memory, and high-performance SSDs. Still, BaM faces major challenges: limited hardware compatibility, conflicts with disaggregated infrastructure, and the high cost of achieving 100 million IOPS. Finally, the author outlines four directions for future exploration: promoting SSD-centric architecture, introducing specialized hardware modules to share I/O tasks, redesigning hardware integration between GPUs and flash, and evolving toward accelerator–NIC–SSD direct access architecture.
Main Article
In the first half of 2025, a friend introduced me to NVIDIA's Big Accelerator Memory (BaM) and Scaled Accelerated Data Access (SCADA) technologies and showed me a demo for a GPU's direct access to SSDs—achieving 100 million IOPS. To put that in perspective, today's top-of-the-line PCIe 5.0 SSDs manage only about 3 million IOPS (14 GB/s), and Micron's new PCIe 6.0 9650 series reaches roughly 5.5 million IOPS (28 GB/s). The demo's numbers were truly eye-opening—like watching a brick fly through the air with unbelievable power.
For anyone who has followed storage development over the years, this result is not entirely surprising, though. The main authors behind BaM—two PhD students of Professor Wen-mei Hwu—joined NVIDIA right after graduation. It was only a matter of time before something big emerged. As someone with over ten years of experience in storage and as someone prone to wild thinking, I'd like to share my thoughts on GPU–SSD direct access technology and explore its past, present, and future.
I. The Past: Everything Leaves a Trail
Back in 2021, Professor Guangyu Sun at Peking University, the guest editor of CCF Transactions on High Performance Computing (THPC), asked me to write a review of GPU–SSD direct access technology, considering my entire PhD revolved around exploring wild ideas in integrating accelerators with SSDs at the system and architecture levels. In a sense, this review is also a partial reflection on my doctoral journey. If anyone is curious, you can check it out.[1]
The original sin of traditional CPU-centric architecture
Researchers in computer architecture are well aware that each year many papers at the major architecture conferences critique traditional CPU-centric designs. These designs often leave CPUs overwhelmed when handling I/O tasks. CPU vendors have quietly added various patches, such as South Bridge, Direct Memory Access (DMA), and Data Streaming Accelerator (DSA). However, these solutions are just sticking plasters. As peripheral device performance continues to improve, the limitations of CPU capabilities become increasingly pronounced.
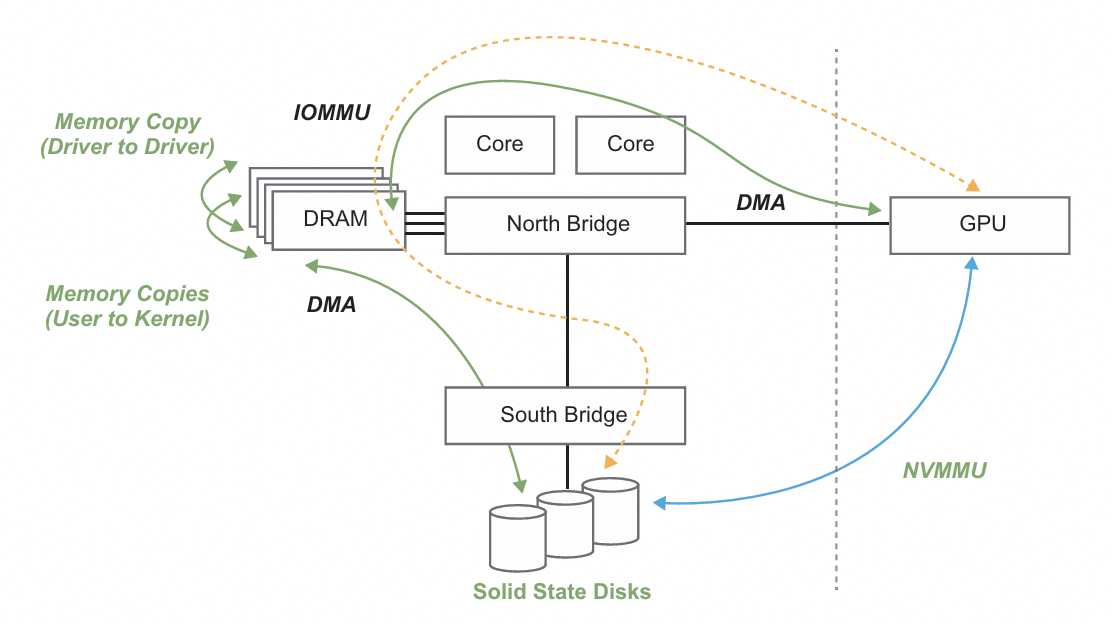
Figure 1 Communication between GPU and SSDs in traditional architecture (red arrows) vs. an ideal architecture (blue arrows). Adapted from [6].
As shown in Figure 1, the core issue of CPU-centric architectures is that all I/O requests must go through the CPU and host DRAM, creating a performance bottleneck on the CPU. Examining this issue more deeply, one can also observe the implications for the design of system software.
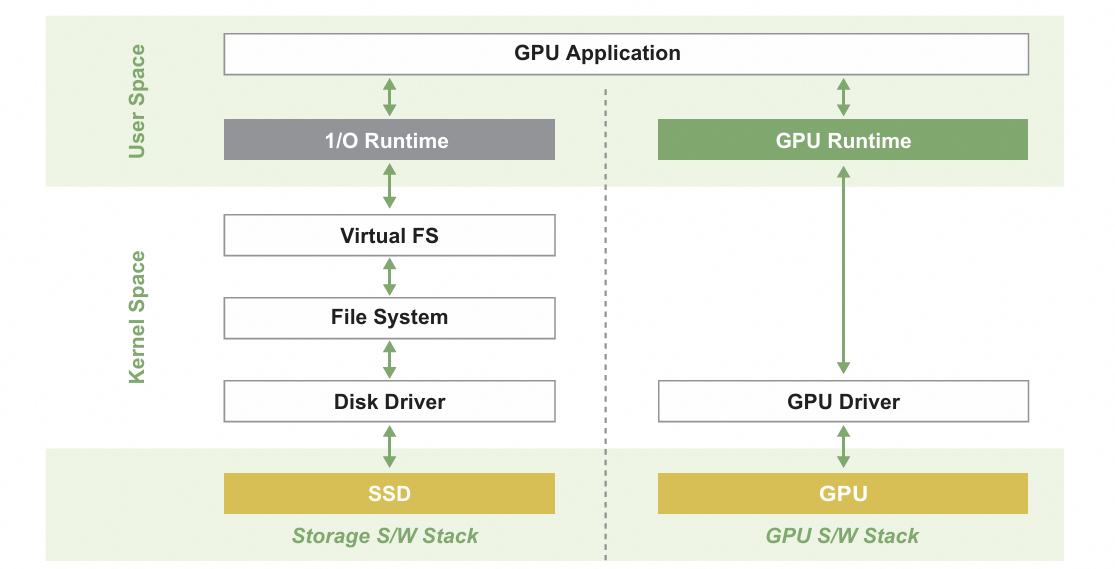
Figure 2 System software stack in traditional architecture. Adapted from [6].
As shown in Figure 2, CPU-centric architectures introduce independent software stacks for each peripheral I/O device, with little interoperability between them. More critically, peripheral I/O devices are managed by the OS kernel, while user applications run in user space, creating a hard boundary between kernel space and user space. Completing a single data transfer between an SSD and a GPU requires traversing a substantial software stack. This includes, but is not limited to, the SSD, the storage software stack, I/O runtime (for example, the NVMe driver, block layer, RAID layer, file system, and virtual file system), GPU runtime, and GPU driver. On top of all that, data does not just pass through the stack, it gets copied repeatedly across layers, from the page cache to the I/O runtime and even the GPU driver. Studies have shown that, in graph computing applications[2] and large language model (LLM) inference[3], data movement alone can take up over 70%—and even 90%—of total execution time.
This problem was first raised by NVIDIA around 2012–2013 and has since sparked more than a decade of sustained discussion in the research community. Looking at how invasive these approaches are to system software and architecture, I broadly categorize the existing work into three directions.
A storage outsider's take: data pipelining
Since the problem was initially raised by researchers specializing in GPUs, it is natural that early optimization efforts approached it from the GPU perspective (not quite from a storage perspective). One intuitive strategy was to introduce pipelining—overlapping data loading from SSDs with GPU kernel execution, or prefetching data from the SSDs—to move storage access off the critical path as much as possible.
To the best of my knowledge, NVIDIA began supporting this programming paradigm as early as Compute Unified Device Architecture (CUDA) 7.0. This idea is actually quite widespread and has been widely adopted in various research works. For example, a recent FAST '26 paper on offloading key-value (KV) cache to SSDs[4] applies fine-grained pipeline optimizations for a specific application scenario, namely KV cache management in LLM inference.
As any computer architecture class would tell us, pipelines only work well when each stage takes about the same time and does not depend on the others—otherwise, you end up with many bubbles. Unfortunately, for the GPU–SSD approach, the data access latency of SSDs is, in most cases, significantly higher than the execution time of GPU kernels. That isn't surprising—data access on SSDs typically involves larger data volumes, which naturally takes time. Flip it around, and if the data volume is small, you probably wouldn't even bother using an SSD. Furthermore, in many scenarios, data to be accessed must be determined at runtime (for example, in LLM Mixture-of-Experts, or MoE). Consequently, even with perfectly overlapped execution, SSD access latency remains difficult to fully hide.
Given that data movement accounts for the majority of execution time, a common approach has emerged based on a simple principle: leverage computing for more storage space. For example, Microsoft proposed DirectStorage for its Xbox platform. With this approach, the GPU compresses and decompresses the data stored on SSDs, cutting down the amount of data that needs to move between the GPU and SSDs. Consequently, data loading time on SSDs is reduced, enabling the pipeline to operate efficiently.
Nowadays, with LLMs everywhere, handling data sparsity essentially follows the same idea of leveraging computing for more storage space—just swapping out compression and decompression for corresponding data processing. But what's the catch? It still ends up wasting GPU computing resources. NVIDIA GPUs are expensive and using them for unrelated tasks seems unnecessarily costly. However, this approach has an advantage—it minimally intrudes on system software, making deployment relatively easy.
Changes to the data path: data plane direct access
One approach that is intrusive to the system software but delivers immediate benefits is direct data plane access, as exemplified by GPUDirect Storage (GDS). In traditional systems, SSDs read and write data to or from host DRAM via DMA. In contrast, GDS uses the PCIe peer-to-peer (P2P) technology to expose GPU local memory as a PCIe address space through the GPU's Base Address Register (BAR). This enables SSDs to read from and write directly to GPU memory via DMA. There are three advantages to this approach: fewer data copies on the CPU side, reduced CPU workload, and reduced pollution for the CPU's L3 cache. Although GDS significantly improves the data path, some researchers question its efficacy.
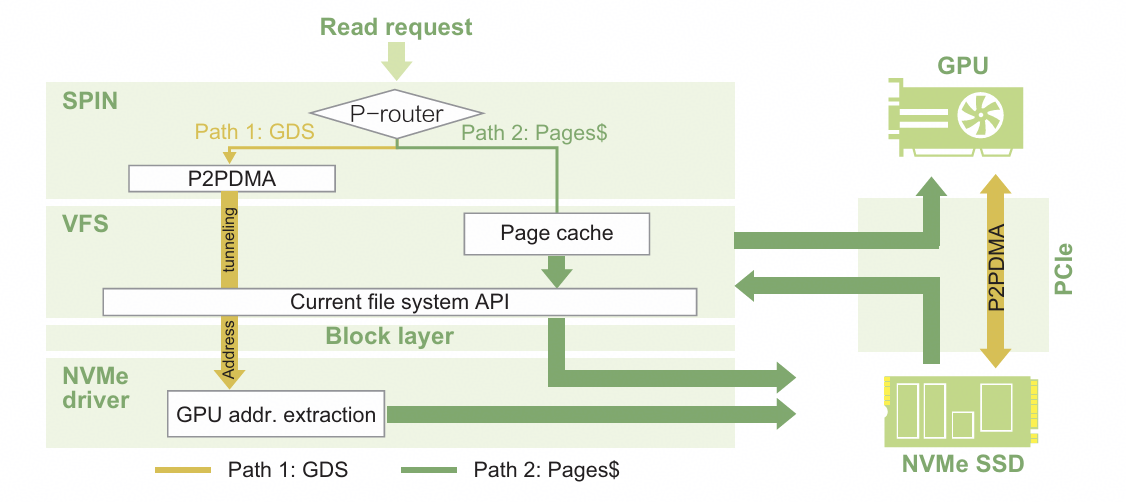
Figure 3 The SPIN architecture adds a page cache as a data buffer outside the GPU–SSD data path. Adapted from [1].
As shown in Figure 3, the conventional GPU–SSD direct access solution (path 1: GDS) suffers from slow SSD response. If data exhibits temporal locality, it is more efficient to cache it in the page cache than to repeatedly load the same dataset from the SSD, as host DRAM is significantly faster than SSDs[5].
Changes to the control path: control plane direct access
GPU–SSD data plane direct access is possible with GDS, so control plane direct access is also possible. Early work such as the non-volatile memory management unit (NVMMU) attempted to achieve this by intrusively modifying the existing system software (see Figure 4).
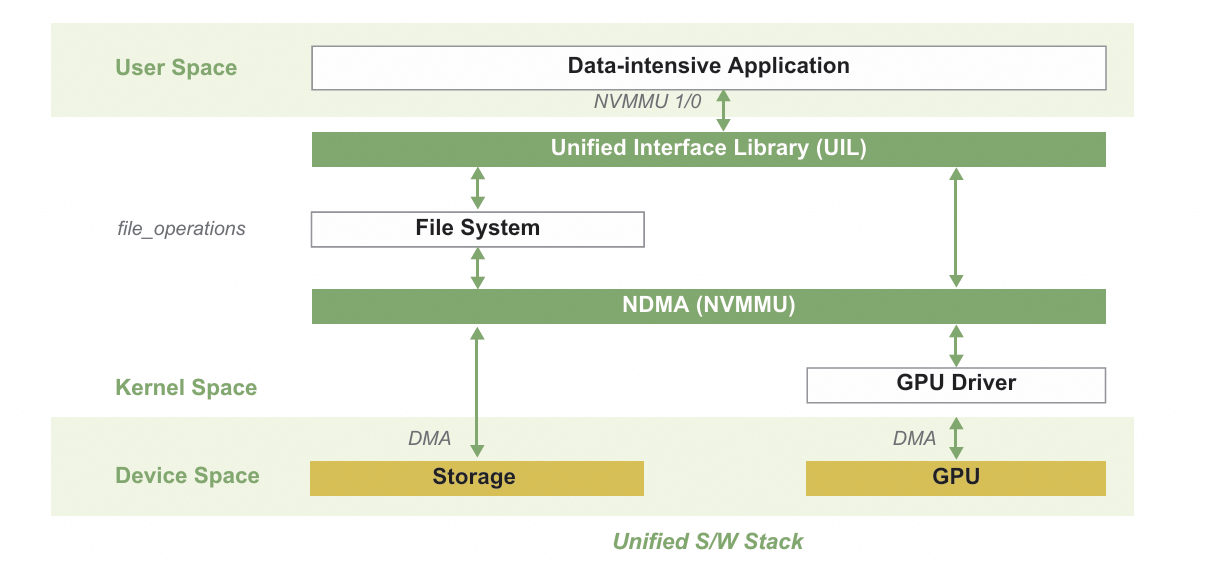
Figure 4 NVMMU's system software design. Adapted from [6].
This NVMMU approach tries to connect the storage software stack with the GPU software stack. After data is read from SSDs to the host, it is stored in a dedicated kernel-space buffer and then transferred directly to the GPU's onboard memory through DMA. With this design, data no longer needs to move between the storage and the GPU software stacks. This eliminates unnecessary memory copies. In addition, NVMMU uses a dedicated unified runtime to send simplified instructions for GPU–SSD data transfers to the system software. Because data does not need to be copied to user space, this further reduces memory copies. In essence, NVMMU offloads GPU–SSD data transfer tasks entirely to the system software, while integrating the two kernel-space software stacks.
Another approach takes the opposite direction, drawing on the popular user-space system software model, as exemplified by the Storage Performance Development Kit (SPDK). In this model, all GPU–SSD data transfer tasks are handled by user-space applications. User space provides greater flexibility to modify control logic, but it also increases development complexity.
Both approaches are built on a CPU-centric architecture and focus on improving the system software. However, neither can achieve GPU–SSD direct access at the control plane. This brings us to the focus of this article: BaM.
Technical summary
|
Technical Approach |
Description |
Pros |
Cons |
|
Data pipeline |
Optimization is done on the GPU side. Only the data processing process is scheduled or transformed. The hardware data path and control logic are not modified. Optimizations are based on the existing architecture. |
Minimum intrusion into the system software makes deployment and implementation straightforward. A general programming paradigm that can be adapted to specific applications like LLM inference. |
SSD access latency is significantly higher than GPU execution time, which makes pipeline latency difficult to hide. Expensive GPU compute resources may be occupied inefficiently, wasting computing power. Preloading strategies are ineffective for real-time data access. |
|
Data plane direct access
|
The hardware data transfer path is modified to enable direct connectivity between the GPU and SSD data planes, improving the physical data path. |
Data copies on the CPU side and CPU workload are reduced. CPU L3 cache pollution is avoided and overall caching efficiency is improved. Data transfer efficiency is improved significantly. |
Intrusive to system software. Slow SSD response is not addressed. When data with temporal locality is repeatedly accessed, this approach can be slower than a page cache–based solution. |
|
Control plane direct access |
The hardware data path remains unchanged. The control logic is optimized for efficiency. The storage and GPU control planes are interconnected to optimize the software control process for data transfers. |
Redundant memory copies between the storage and GPU software stacks are reduced to improve transfer efficiency. A unified runtime simplifies transfer instructions. NVMMU reduces kernel-space overhead. SPDK enables high user flexibility for modifying control logic. |
Highly intrusive to system software, requiring significant changes to the existing architecture. The SPDK solution greatly increases development complexity. CPU dependency is not fully eliminated, as the approach is based on the traditional CPU-centric architecture. |
II. Determinism and Uncertainty of GPU–SSD Direct Access
BaM is the final piece of the puzzle for GPU–SSD direct access. As shown in Figure 5, it integrates selected page cache functionalities and the core functions of the NVMe driver into the GPU. When a GPU warp or thread initiates an I/O request, it first checks the GPU's local cache (data buffers). On a cache hit, the data is returned immediately (as indicated by the green path in the figure). On a cache miss, a GPU-customized NVMe driver is invoked.
The NVMe driver allows the GPU warp to construct NVMe submission and completion queues (SQs/CQs) directly in the GPU's on-board memory and issue NVMe commands. It also supports doorbell ringing and direct polling of NVMe CQ messages (the red path in the figure). With this design, the CPU can be bypassed. Administrative commands and queues are still initialized and managed by the CPU, but this has minimal impact on overall performance. As a result, the GPU can fully utilize the available SSD bandwidth.
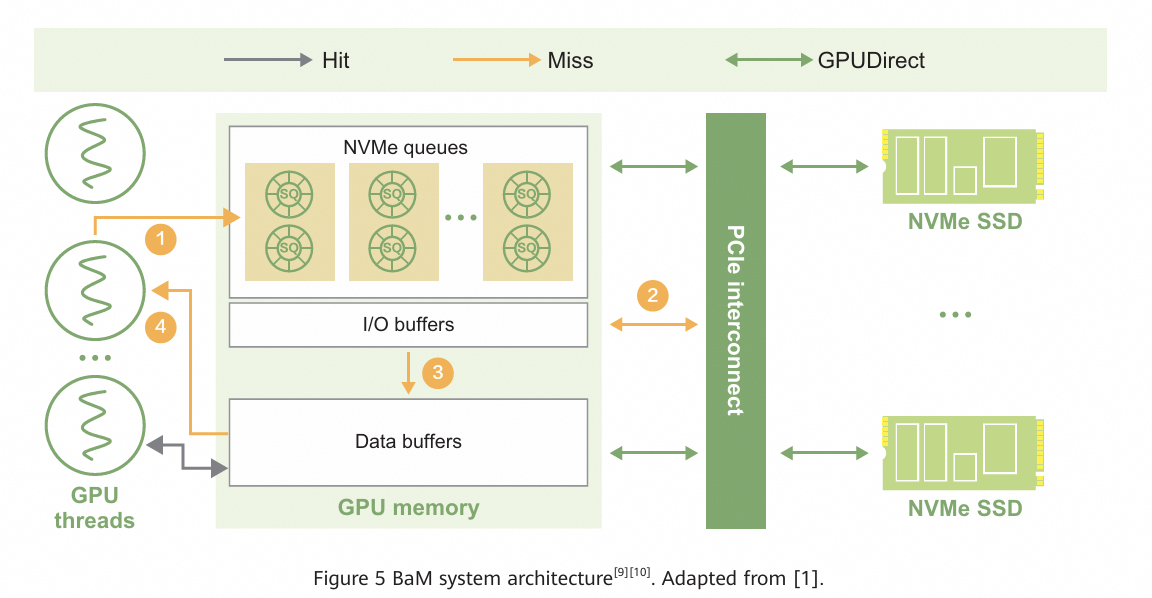
Figure 5 BaM system architecture[9][10]. Adapted from [1].
Determinism
BaM is a good example of how future computer systems can be designed. It demonstrates that the traditional CPU-centric architecture can be replaced to move from a three-party CPU–SSD–GPU model to a more direct and streamlined two-party GPU–SSD model. However, BaM is not without limitations. In its current form, it is more of a laboratory toy than a production-ready system. BaM is very similar to SPDK: it primarily integrates NVMe drivers and simplified page cache, and treats SSDs as raw disks. That said, the research path for BaM is clear.
l To use SSDs as traditional storage devices, you need to add the missing storage software stack to BaM.
l To use SSDs as the secondary storage, you need to add a tiered memory management system.
l If the performance of PCIe 5.0 SSDs is insufficient, future designs could focus on developing SSDs with higher throughput and lower latency.
Research in these areas has been underway for the past year.
l A team led by Zhang Yiming at Shanghai Jiaotong University proposed GeminiFS[7], which caches the mappings between file names and addresses in the file system on the GPU. In this way, the GPU can implement the functions of the traditional file system by looking up tables. A team led by Jian Huang at the University of Illinois at Urbana-Champaign (UIUC) went further by directly integrating a complete file system into the GPU, known as GoFS[8].
l A team led by Wen-mei Hwu at the same institution developed a tiered memory system based on HBM–DRAM–SSD and its management framework[20].
l In China, Unigroup is planning high-bandwidth flash (HBF) to provide ultra-low I/O latency.
l In 2017, Samsung introduced a low-latency flash chip called ZNAND flash, which was later discontinued due to limited market demand. With the emergence of BaM, SCADA, and increased industry momentum driven by NVIDIA, Samsung resumed ZNAND research in 2025.
Companies like Kioxia, Micron, and SK Hynix have claimed to have developed SSDs capable of delivering up to 100 million IOPS.
Uncertainty
The year 2025 saw strong interest from both academia and industry in BaM architecture. However, there is uncertainty as to whether BaM architecture will have the same appeal in 2026.
GPU–SSD direct access is currently designed only for NVIDIA's professional GPUs. At present, BaM can run reliably only on a limited set of high-end NVIDIA GPUs, because NVIDIA provides larger BAR space for these high-end GPUs. It is unclear whether BaM can be extended to NVIDIA's low-end GPUs or GPUs from other vendors. The logic behind this is simple. Vendors tend to optimize new technologies around their own ecosystems, creating a moat to protect themselves. Everyone agrees that AI is the future, but whether GPUs are the future of AI is still uncertain.
In my opinion, we will see development toward a more diverse set of accelerators, including DPUs, 8-NPUs, xPUs, and near-memory computing. In this context, it may be necessary to consider accelerator–SSD direct access, rather than focusing solely on GPU–SSD direct access. This raises a question: Do we need to design a BaM-like architecture for each type of accelerator?
Second, GPU–SSD direct access technology is not inherently dependent on disaggregated architectures. In 2025, another widely discussed technology was scale-up networking, also known as supernode bus interconnection. Representative examples include Compute Express Link (CXL)[11] and Huawei's Unified Bus (UB)[12]. For the disaggregated architecture built on these technologies, resource disaggregation is one of the effective solutions for cloud vendors to improve resource utilization. Scale-up networking significantly reduces the cost of node interconnection, making resource disaggregation more practical.
According to this trend, GPUs are expected to evolve into accelerator pools, while SSDs will form storage pools. This direction differs from BaM architecture, which is designed around GPU–SSD direct access. In contrast, disaggregated architectures are likely to move toward a GPU–NIC–SSD model. In addition, BaM architecture assumes a relatively tight coupling between GPUs and SSDs, whereas disaggregated architectures require multiple GPUs and multiple SSDs to share resources, which increases design complexity.
Some may argue that BaM acts as a node-local cache in the entire memory hierarchy. GPU nodes can still access the storage pool through the Internet, serving as the last layer of the memory hierarchy. Compared with a storage pool, BaM can offer lower latency and higher throughput.
In my view, with the increasing popularity of supernodes, if NIC bandwidth approaches PCIe bandwidth levels, and network latency is significantly lower than SSD I/O access latency, the necessity of maintaining local SSDs and BaM architecture within the memory hierarchy becomes less certain.
Finally, achieving 100 million IOPS entails significant cost, including both SSD and GPU-related expenses.
For SSDs, an enterprise-class PCIe 5.0 SSD can currently provide up to 3 million IOPS, with five Arm cores required to handle firmware tasks. Scaling to SSDs capable of delivering 100 million IOPS would likely need more than 160 Arm cores. Currently, only the server-level Arm processors can meet this demand—and only barely—which would result in extremely high costs, power consumption, and footprint. In addition, the bandwidth of an SSD's onboard memory presents another challenge. This memory needs to cache read/write data during DMA operations. In addition, when executing firmware tasks such as those performed by the flash translation layer (FTL), metadata in the onboard memory is frequently accessed. These requirements place considerable bandwidth pressure on the SSD's onboard memory. Given these constraints, is it worth designing a high-performance SSD capable of delivering 100 million IOPS based on existing SSD architectures?
On the GPU side, BaM architecture consumes GPU compute resources to perform I/O tasks, including NVMe queue management, I/O completion polling, and I/O and data buffer management. Although the specific compute overhead of BaM architecture has not been measured, a report from DeepSeek outlines the GPU compute requirements for network I/O tasks. Performing these I/O tasks requires GPUs to handle additional data movement and control overhead. This report can be used as a reference to evaluate the impact of BaM on GPU compute resources. According to the report, up to about 15% of the compute cores of an NVIDIA H800 GPU are allocated to I/O processing tasks.[13] This raises the question of whether occupying valuable compute cores on expensive GPUs is justified to achieve GPU–SSD direct access.
III. Outlook and Perspectives
I have discussed a number of ideas with my lab colleagues regarding these questions. For further details, readers may refer to the papers and articles published by our lab. Below, I briefly outline several perspectives.
l Over the past few years, I have been promoting an SSD-centric architecture within both academic and industrial communities, as this approach can effectively address challenges associated with BaM architecture. From this perspective, an SSD can be viewed as a mini computer subsystem. Its firmware functions in a manner analogous to a simplified OS. The FTL can be regarded as a simplified file system or KV engine. And the queues in the host interface layer (HIL) and flash interface layer (FIL) are similar to the queues in the block layer and NVMe driver layer of a traditional OS. Based on this abstraction, integrating the storage software stack with SSD firmware enables the entire storage software stack to be offloaded to the SSD, without introducing additional burden to SSD controllers. I have been conducting research in this direction and, for further details, please refer to the relevant works.[14] [15] The key advantage of this approach is that accelerators only need to incorporate the most lightweight storage software stack to achieve direct access to SSDs, eliminating the need for extensive migration for each new accelerator.
l Since processing I/O tasks on GPUs incurs significant overhead, an important question is whether other devices can be used to assist with such processing. This opens up a range of potential approaches. One option is to design an Application-Specific Integrated Circuit (ASIC) and place it along the data path to handle part of the I/O processing. This approach is conceptually similar to the IOMMU accelerator proposed by Professor Jaewoo Kim's team at Seoul National University in South Korea. For further details, readers may refer to the corresponding paper.[15] Another approach is to modify devices such as SmartNICs or DPUs. I have also explored similar ideas over the past two years.[18]
l Processing massive I/O tasks on SSDs also introduces significant overhead. This raises the question of whether such tasks can be offloaded away from SSDs. In this context, I would like to reference my own work.[2] [17] The core idea is to remove the traditional SSD controller and onboard memory and, instead, integrate the flash storage array and channels into the GPU, enabling the GPU to execute firmware-related tasks. As noted earlier, GPU-based I/O processing also incurs overhead. To address this, the firmware logic is significantly simplified so that it can be combined with the GPU's compute tasks, minimizing the overhead. Subsequently, the team at Seoul National University adapted and modified this approach for DNN training scenarios, but the overall concept is very similar.[19]
l Finally, evolving from GPU–SSD direct access to an accelerator–NIC–SSD direct access model is one of the most direct and easiest-to-implement solutions to adopt disaggregated architectures. One key advantage of this model is that it avoids the need to design an AI SSD capable of delivering 100 million IOPS. Instead, the storage pool can dynamically allocate the required I/O bandwidth to accelerators and the bandwidth of the scale-up network is also sufficient. In addition, the cache coherency in the scale-up network (a feature of CXL 3.0, although no hardware is available yet) enables data sharing across multiple accelerators, alleviating the limitations of BaM architectures where SSDs are typically bound to a specific GPU. However, our lab encountered challenges during practical implementation but that is beyond the scope of this discussion. Detailed design considerations will be presented in future work.
Access Data Dialogue, Issue 002 →
Reference
[1] Z. Zhou, S. Yi, and J. Zhang, "Survey on storage-accelerator data movement," CCF Trans. High Perform. Comput., vol. 4, no. 4, pp. 435–447, 2022.
[2] J. Zhang and M. Jung, "ZnG: Architecting GPU multi-processors with new flash for scalable data analysis," in ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA 2020), IEEE, 2020.
[3] X. Pan, E. Li, Q. Li, S. Liang, Y. Shan, K. Zhou, Y. Luo, X. Wang, and J. Zhang, "InstAttention: In-storage attention offloading for cost-effective long-context LLM inference," in 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pp. 1510–1525, IEEE, 2025.
[4] X. Zheng, D. Wei, J. Gao, Y. Song, Z. Mi, and H. Chen, "SolidAttention: Low-Latency SSD-based Serving on Memory-Constrained PCs," in USENIX Conference on File and Storage Technologies (FAST), 2026.
[5] S. Bergman, T. Brokhman, T. Cohen, and M. Silberstein, "SPIN: Seamless operating system integration of peer-to-peer DMA between SSDs and GPUs," ACM Trans. Comput. Syst. (TOCS), vol. 36, no. 2, pp. 1–26, 2019.
[6] J. Zhang, D. Donofrio, J. Shalf, M. T. Kandemir, and M. Jung, "Nvmmu: A non-volatile memory management unit for heterogeneous GPU-SSD architectures," in 2015 International Conference on Parallel Architecture and Compilation (PACT), pp. 13–24, IEEE, 2015.
[7] S. Qiu, W. Liu, Y. Hu, J. Yan, Z. Shen, X. Yao, R. Chen, G. Zhang, and Y. Zhang, "GeminiFS A Companion File System for GPUs," in the 23rd USENIX Conference on File and Storage Technologies (FAST 25), pp. 221–236. 2025.
[8] S. Li, Y. E. Zhou, Y. Xue, Y. Xu, and J. Huang, "Managing scalable direct storage accesses for GPUs with GoFS," in ACM SIGOPS 31st Symposium on Operating Systems Principles (SOSP), pp. 979–995. 2025.
[9] Z. Qureshi, V. S. Mailthody, I. Gelado, S. Min, A. Masood, J. Park, J. Xiong et al., "BaM: a case for enabling fine grain high throughput GPu-orcharted access to storage,"ArXiv preprint arXiv:2203.04910, 2022.
[10] Z. Qureshi, V. S. Mailthody, I. Gelado, S. Min, A. Masood, J. Park, J. Xiong et al., "GPU-initiated on-demand high throughput storage access in the BaM system architecture," inThe 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vol. 2, pp. 325-339, 2023.
[11] Y. An, S. Yi, B. Mao, Q. Li, K. Zhou, and N. Xiao, "Xerxes: extensive exploration of scalable hardware systems with CXL-based simulation framework," inUSENIX Conference on File and Storage Technologies (FAST), 2026.
[12] H. Liao, B. Liu, X. Chen, Z. Guo, C. Cheng, J. Wang, X. Chen et al., "UB-Mesh: A hierarchically located nD-FullMesh data center network architecture,"IEEE Micro, 2025.
[13] C. Zhao, C. Deng, C. Ruan, D. Dai, H. Gao, J. Li et al., "Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures,"ArXiv preprint arXiv:2505.09343, 2025.
[14] L. Peng, Y. An, Y. Zhou, C. Wang, Q. Li, C. Cheng, and J. Zhang, "ScalaCache: Scalable user-space page cache management with software-hardware coordination," in2024 USENIX Annual Technical Conference (USENIX ATC 24), Pp. 1185-1202, 2024.
[15] S. Yi, X. Bread, Q. Li, Q. Li, C. Wang, B. Mao, M. Jung, and J. Zhang, "ScalaAFA: constructing user-space all-flash array engine with holistic designs," in2024 USENIX Annual Technical Conference (USENIX ATC 24), Pp. 141-156, 2024.
[16] J. Ahn, D. Kwon, Y. Kim, M. Ajdari, J. Lee, and J. Kim, "DCS: a fast and scalable device-centric server architecture," inThe 48th International Symposium on Microarchitecture, Pp. 559-571, 2015.
[17] J. Zhang, M. Kwon, H. Kim, H. Kim, and M. Jung, "FlashGPU: placing new flash next to GPU cores," inThe 56th Annual Design Automation Conference, Pp. 1-6. 2019.
[18] X. Bread, Y. An, S. Liang, B. Mao, M. Zhang, Q. Li, M. Jung, and J. Zhang, "Flagger: cooperative acceleration for large-scale cross-silo federated learning aggregation," in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), Pp. 915-930. IEEE, 2024.
[19] S. Kim, Y. Jin, G. Sohn, J. Bae, T. J. Ham, and J. W. Read, "Behemoth: A flash-centric training accelerator for extreme-scale DNNs," inThe 19th USENIX Conference on File and Storage Technologies (FAST 21), Pp. 371-385, 2021.
[20] C.-H. Chang, J. Han, A. Sivasubramaniam, V. S. Mailthody, Z. Qureshi, and W.-M. Hwu, "GMT: GPU orbited memory tiering for the big data era," inThe 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vol. 3, pp. 464-478, 2024.
