张杰 | 北京大学计算机学院 研究员
—— 本文收录于《Data Dialogue · 第2期》
【摘要】本⽂围绕 GPU-SSD 直通技术展开深度剖析,探究其发展脉络与产业价值。⽂章先追溯技术前世,指出传统以 CPU 为中⼼的架构存在 IO 请求过度依赖 CPU 、软件栈割裂、数据传输开销极⾼的核⼼问题,学界和产业界由此从流⽔线优化、数据通路 / 控制通路改动等⽅向探索优化,为 GPU-SSD 直通奠定基础。接着聚焦当下主流的 BaM 技术,它实现 了 GPU 对 SSD 的 CPU 旁路访问,带来架构⾰新的确定性,多家企业和⾼校也围绕其推进存储软件栈、分层内存、⾼性能 SSD 等配套研发。但该技术也存在硬件适配局限、与分离式架构冲突、 1 亿 IOPS 实现成本过⾼的三⼤不确定性。最后作者提出四个未来探索⽅向,包括推⼴SSD-centric 架构、引⼊专⽤芯⽚分担 IO 任务、重构 GPU 与闪存硬件集成、改造加速器 - NICSSD 直通架构,为该技术及下⼀代加速器存储协同架构发展提供了多元思路。
⼀、引言
25 年上半年,⼀个朋友向我分享了⼀波英伟达公司的 BaM 、SCADA 技术,给我展⽰了英伟达公司的 demo,说这个技术能让GPU 直接访问 SSD ,达到 1 亿 IOPS 。要知道现在市⾯上能买到的 PCIe 5.0 固态盘最多也就是 300 万 IOPS( 14GB/s ), 镁光刚推出的 PCIe 6.0 固态盘 9650 系列应该是 550 万 IOPS ( 28GB/s )。这个技术的效果确实是⾮常震撼,有⼀种“⼒⼤砖⻜”数值上的美。但是对常年关注存储发展的⼈来说,其实也在意料之中。毕竟 Wen-mei Hwu 的两个博⼠⽣,也就是BaM 的主要作者,⼀毕业就进了英伟达,我想着早晚会整点⼤活。作为⼀个⼗年存储⼈同时也是爱胡思乱想瞎做梦的研究者,我来分享⼀下我对 GPU-SSD 直通技术的看法,探究⼀下它的前世、今⽣和未来。
⼆、前世:⼀切都有迹可循
21年THPC 期刊的客座编辑、北⼤的孙⼴宇⽼师邀请我给 GPU-SSD 直通技术写⼀个综 述。为什么选择是我呢?因为我的⼀整个博⼠⽣涯围绕着加速器和固态盘的系统和架构集 成做了各种开脑洞的探索,这篇综述其实也是在部分回顾我的博⼠⽣涯,⼤家感兴趣的话 可以围观⼀下【1】。
传统 CPU-centric 架构的原罪
接触体系结构的研究者应该很清楚,每年体系结构四⼤会都有不少论⽂会批判传统 CPU centric 架构,因为这种设计导致 CPU 在处理 IO 任务的时候真的忙不过来。其实 CPU ⼚商也默默做了很多补丁,⽐如南桥(South Bridge)、DMA 、data streaming accelerator (DSA)。但是这些补丁也是治标不治本,随着外围设备的性能不断提升, CPU 能⼒不⾜ 的问题会变得更加突出。
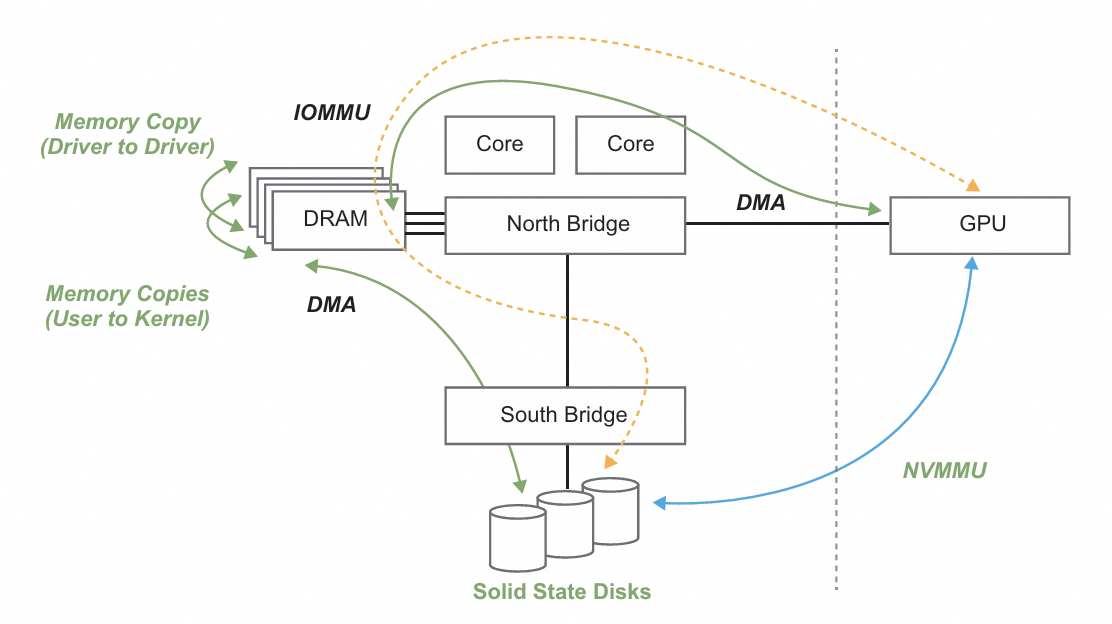
图 1 :传统架构中 GPU 与 SSD 的通信(红⾊箭头) vs 理想架构中 GPU 与 SSD 的通信(蓝⾊ 箭头)。图⽚引⾃【6】
如图 1 所⽰,CPU-centric 架构的核⼼问题是所有的 IO 请求都需 要通过 CPU 和 host DRAM 捣⼀⼿,导致性能全卡在 CPU 侧了。如果挖的更深⼊⼀点,我们可以看系统软件的设计。
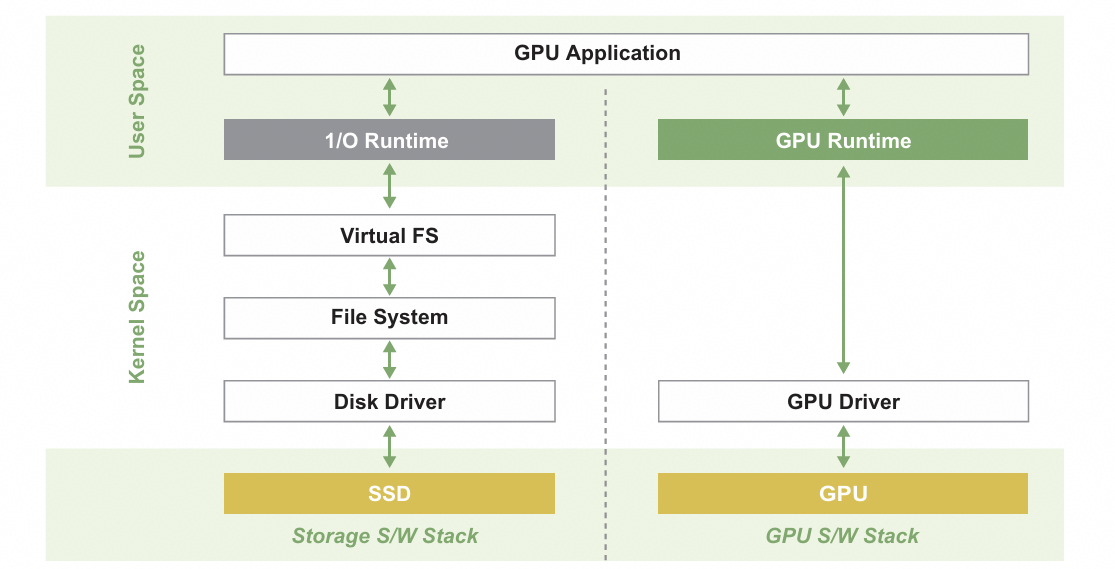
图 2 :传统架构中的系统软件栈。图⽚引⾃【6】
如图 2 , CPU-centric 架构给每个外围 IO 设备都整了独⽴的软件栈,软件栈之间彼此不互通。更加令⼈崩溃的是,外围 IO 设备是操作系统内核接管的,⽤户应⽤程序是跑在⽤户态的,内核态和⽤户态彼此不互通。完成⼀次 SSD-GPU的数据发送,需要爬的软件层是⾮常客观的,包括但不限于: SSD — 存储软件栈 — IO 运⾏时 ( NVMe 驱动、块层、阵列层、⽂件系统、虚拟⽂件系统) — GPU 运⾏时 — GPU 驱动。另外,在整个传输过程中,数据也需要在多个软件层进⾏反复拷⻉,包括但不限于 page cache 、 IO 运⾏时、 GPU 驱动。⼀系列的实验表明在图计算应⽤【2】和 LLM 推理 场景【3】中,数据传输的开销占了整个应⽤执⾏时间的 70% 和 90% 以上。
这个问题最早应该是英伟达在12 年或者 13 年提出来的,在学术圈引发了持续⼗年以上的讨论。我根据对系统软件和架构的侵⼊性,⼤致把研究⼯作分为以下三个⽅⾯向。
存储门外汉的优化尝试:数据流⽔线
其实问题的提出者是⼀帮做 GPU 的专家,所以⾮常理所当然地,他们也直接从 GPU 的⾓ 度做了优化尝试(ps:他们不懂存储,所以我叫他们存储门外汉)。⼀种最直观最⾃然的想法就是做流⽔线,把 SSD 侧的数据加载过程和 GPU kernel 执⾏过程重叠,或者对 SSD 侧的数据进⾏预加载,让 SSD 侧的数据访问尽可能搬离 critical path 。
据我了解,英伟达最早是在⾃家的 CUDA7 就开始⽀持这样的编程范式。当然这个思想其实⾮常通⽤,在各种研究⼯作⾥被反复地⽤,⽐如今年 FAST26 的 KV cache 卸载 SSD ⼯作【4】也是做了针对特定应⽤(即 LLM 推理中的 KV cache )做了流⽔线的精细优化。
学过体系结构课的朋友们,⼀定知道流⽔线要想跑起来⾼效,必须要每个 stage 的时间都 差不多,同时彼此之间没有依赖关系,这样 bubble 最少。很遗憾的是,对于 GPU-SSD 这对组合再说,SSD 的数据访问延迟在⼤部分情况下是远⾼于 GPU kernel 的执⾏时间 (ps:这个现象也⽐较符合直觉,因为 SSD 侧的数据访问量⼀般会⽐较⼤,⽐较耗时间。反过来说,如果数据量少的话也⽤不上 SSD )。⽽且很多时候要访问什么数据是需要实时算出来的(如 LLM MoE )。这导致的问题是,即使做了最完美的重叠, SSD 的数据访问延迟还是很难被隐藏起来。
既然数据传输占了总时间的⼤头,那么还有⼀种很常⻅的⽅案就流⾏起来了,核⼼思想简 单来说就是⽤计算换空间。⽐如说,微软针对⾃家的XBOX 提出来⼀个⽅案叫 Direct Storage 。这个⽅案让 GPU 对需要存在 SSD ⾥的数据进⾏压缩和解压缩,这样需要在 GPU-SSD 之间传输的数据量就能显著降低。进⼀步的,SSD 侧的数据加载时间就能减少,然后流⽔线就能正常流转起来了。在 LLM 流⾏的当下,数据的稀疏其实也是同⼀套 “ 计算换空间 ”的思路,只是把以前的压缩解压操作换成了对应的数据处理操作。 那么,这么做有什么不好的呢?其实还是浪费 GPU 的计算资源。英伟达的 GPU 实在是太贵 了,让它做⼀些⽆关的⼯作,⽼板们得⼼疼半天。这么做其实也有优点,那就是对系统软件的侵⼊度很⼩,部署起来很容易。
数据通路的改动:数据平面直通技术
有⼀种⽅案对系统软件有⼀定的侵⼊性,但是效果⽴竿⻅影,那就是以 GPU Direct Storage ( GDS )为代表的数据平⾯直通技术。传统系统是让 SSD 通过 DMA 从 host DRAM 的内存空间⾥读写数据。 GDS 技术的本质是 PCIe P2P ( Peer-to-Peer )技术,让 GPU 通过 PCIe BAR ( base address register )暴露⼀段本地的内存空间作为 PCIe 地址空间。 SSD 同样可以通过 DMA 从 GPU 内存空间⾥读写数据。这么做的好处有⼏点。⾸先是减少了数据在 CPU 侧的多次拷⻉,其次是减少了 CPU 的负担,最后是减少 CPU L3 cache 的污染。其实 GDS 对于优化数据路径已经做得⽐较优雅了,当然学术圈的反⾻仔还提出了⼀些不同的观点。
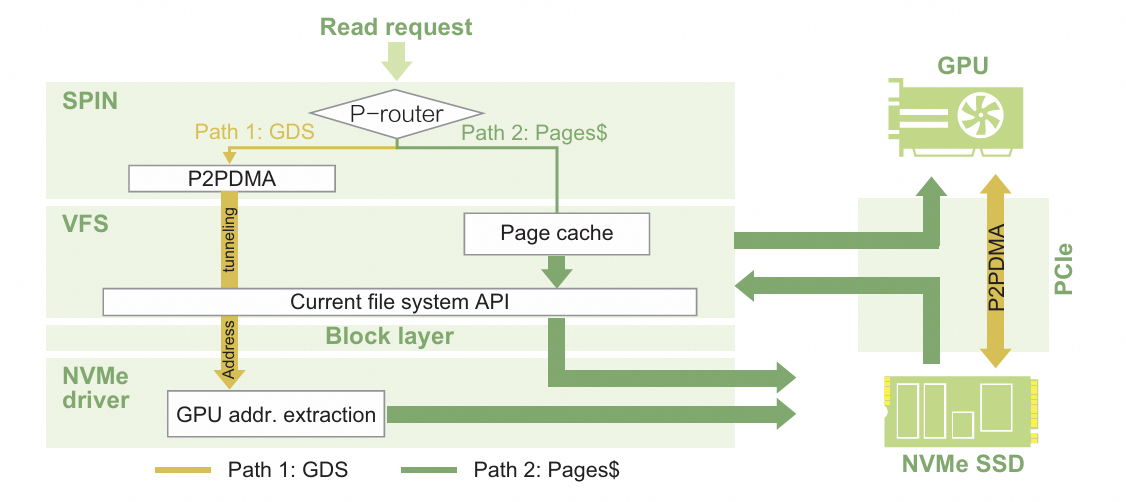
图 3 : SPIN 架构在 GPU-SSD 的数据通路之外加⼊了 page cache 作为数据缓冲区。图⽚引⾃【1】
如图 3 所⽰,传统 GPU-SSD 直连的⽅案(Path 1: GDS )还是会⾯临 SSD 响应太慢的问题。如果数据具有⼀定的时间局部性,重复从 SSD 加载同⼀组数据,不如把数据缓存在 page cache 上,因为主机端的 DRAM 还是⽐ SSD 快不少【5】。
控制通路的改动:控制平⾯直通技术
既然 GDS 能够实现 GPU-SSD 之间数据⾯的直通,对控制⾯实现直通也是呼之欲出。初期的⼯作尝试对现有的系统软件进⾏⼀定侵⼊性的改造,⽐如 NVMMU (⻅图 4 )。
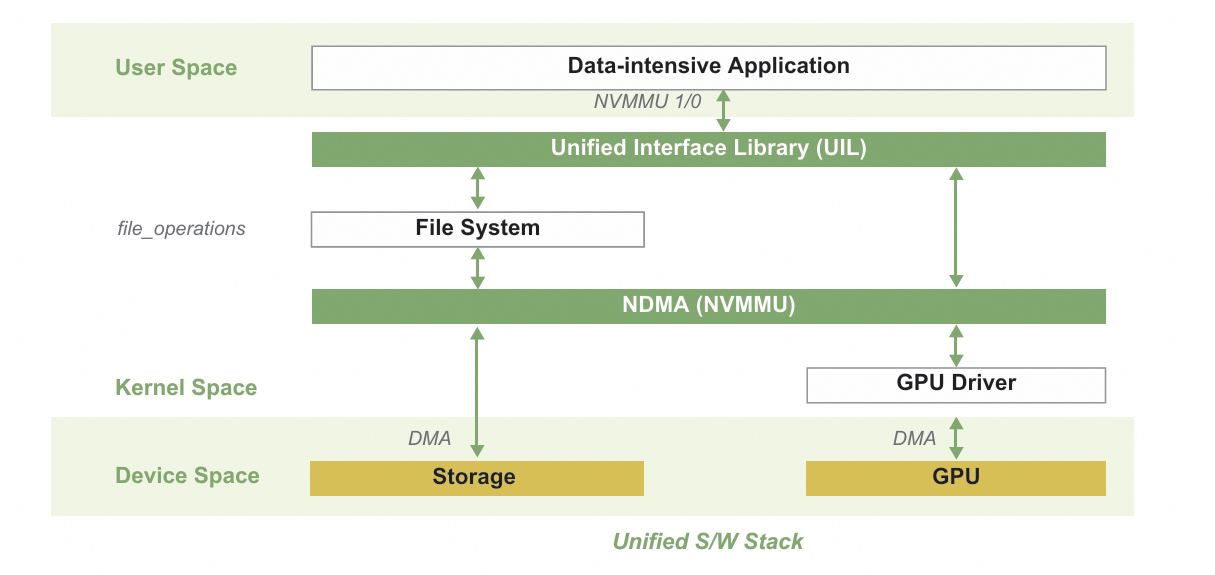
图 4 :NVMMU 的系统软件设计。图⽚引⾃【6】
这个⼯作尝试打通存储软件栈和 GPU 软件栈,数据从 SSD 读到主机侧之后会保留在专⽤的内核态缓冲区,然后直接 DMA 到 GPU 板载内存中。这么做的好处是数据不需要在存储软件栈和GPU 软件栈之间倒腾,少了多余的 memory copy 。另外, NVMMU 开发了专门的统⼀运⾏时,负责给系统软件发送 GPU-SSD 数据传输的精简指令。由于数据不需要拷⻉到⽤户态,⼜省了不少的 memory copy 。 NVMMU 的本质是把 GPU-SSD 数据传输⼯作全部让系统软件独⽴去完成,同时融合内核态的两个软件栈。另⼀个⼯作正好反其道⽽⾏,主要借鉴的是当下很⽕的⽤户态系统软件开发思路,⽐如 Storage Performance Development Kit ( SPDK )。也就是把 GPU-SSD 数据传输全部交给⽤户态应⽤程序来完成,⽤户态有更⼤的⾃由去修改整个控制逻辑,当然这么做给程序员带来的开发难度就更⼤了。
上⾯说的这两个⼯作还是在 CPU-centric 架构的基础上做系统软件层⾯上的优化,但是跟 GPU-SSD 控制⾯的直通还是有⼀定的差距。这就引出来这篇⽂章的主⾓ BaM 。
它⼭之⽯可以攻⽟:技术总结
|
技术方向 |
关键差异点 |
优势 |
劣势 |
|
数据流水线 |
从 GPU 侧切⼊优 化,仅对数据处理流程做调度/变换,不改动硬 件数据通路和控 制逻辑,完全基于原有架构优化 |
1. 对系统软件侵⼊ 度极低,部署落 地难度⼩; 2. 编程范式通⽤,可 适配 LLM 推理等 特定应⽤场景 |
1. SSD 访问延迟远⾼于 GPU 执⾏时间,流⽔线延迟难以隐藏; 2. 占⽤昂贵的 GPU计算资源,造成算⼒浪费; 3. 实时数据访问场景 下预加载策略失 效 |
|
数据平⾯直通技 术 |
改动硬件数据传输通路,实现 GPU-SSD 数据⾯直连,核⼼优化数据传输的物 理路径 |
1. 减少 CPU 侧数据拷⻉,降低 CPU 负载; 2. 避免 CPU L3 cache 污染,提升整体缓存效率 3. 数据传输效率提升显著,优化效果⽴竿⻅影 |
1. 对系统软件有⼀定侵⼊性; 2. 未解决 SSD 本⾝响应慢的问题, 有时间局部性的数据反复读取时效率不如 page cache 缓存⽅案 |
|
控制平⾯直通技 术 |
不改动硬件通 路,聚焦控制逻辑优化,打通存储- GPU 控制⾯,核⼼优化数据传输的软件控制流程 |
1. 减少存储 / GPU 软件栈间的 多余内存拷⻉, 提升传输效率; 2. 统⼀运⾏时精简 传输指令, NVMMU 降低内 核态开销; 3. SPDK 让⽤户态拥 有控制逻辑修改 的⾼⾃由度 |
1. 对系统软件侵⼊性较⾼,需改造现有软件架构; 2. SPDK ⽅案⼤幅提升程序员的开发难度 3. 仍基于传统 CPU centric 架构优化,未完全脱离 CPU 依赖 |
三、当下: GPU-SSD 直通的确定性和不确定性
某种意义上来说,BaM 的出现算是给 GPU-SSD 直通补上了最后⼀块拼图。如图 5 所⽰, 它把⻚缓存的部分功能和 NVMe 驱动的主要功能彻底集成到 GPU ⾥。 GPU warp/threads 发起 IO 访问,会⾸先查找 GPU 本地的缓存( Data buffers )。如果命中( hit ),则⽴即返回(图中绿线指⽰的部分)。如果未命中( miss ),则调⽤ GPU 定制的 NVMe 驱动。
NVMe 驱动允许 GPU warp 直接在 GPU 板载内存构建 NVMe SQ/CQ 队列并发送 NVMe 指令,同时⽀持 ring doorbell ,并且可以直接轮询 NVMe CQ 的消息(图中红线指⽰的部分)。这么做就基本上能旁路 CPU ( ps: admin 指令和 admin queue 还是 CPU 发起和维护,这个不影响整体性能),让 GPU 完全利⽤好 SSD 的带宽了。
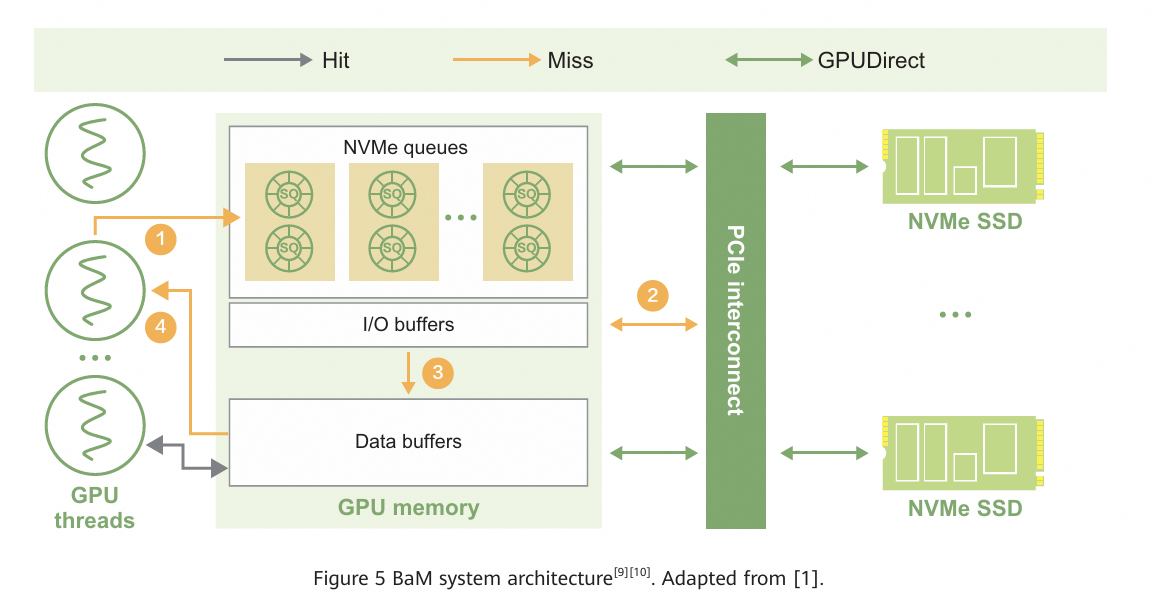
图 5 : BaM 的系统架构设计【9, 10】。图⽚引⾃【1】
GPU-SSD 直通带来的确定性
BaM 其实是给未来的计算机系统设计打了个样,摒弃传统 CPU-centric 架构是完全可⾏的,让 CPU-SSD-GPU 这样的三⽅架构回归最直接⾃然的 GPU-SSD 两⽅架构。 BaM 也不是完美的,你可以认为它还是处于实验室的玩具。 BaM 就⾮常像 SPDK ,⽬前只集成了 NVMe 驱动和简化过的 page cache ,只能拿 SSD 当成裸盘来⽤。但是以 BaM 为基础的研究路线是⾮常确定的。
l 如果想要把 SSD 做成传统的存储设备,就需要给 BaM 补上缺失的存储软件栈;
l 如果把 SSD 做成主存的次级存储,那就需要补上分层内存管理系统;
l 如果觉得当下 PCIe 5.0 SSD 性能不够,那就设计更⾼吞吐、更低延迟的 SSD 。
其实上述这些在 25 年都有学者或者公司在推进了。
l ⽐如国内上交的张⼀鸣⽼师团队提出了 GeminiFS 【7】,把⽂件系统⾥的⽂件名和地址的映射关系缓存在 GPU 上,这样 GPU 可以通过查表的⽅式实现传统⽂件系统的功 能。美国伊利诺伊⼤学⾹槟分校( UIUC )的 Jian Huang ⽼师团队做得更彻底,直接在 GPU ⾥集成了⼀个完整的⽂件系统,叫 GoFS【8】。
l UIUC 的 Wen-mei Hwu ⽼师团队搭建了基于 HBM-DRAM-SSD 的分层内存,并且做了⼀个分层内存管理系统【19】。
l 国内紫光公司说要做 High-Bandwidth Flash ( HBF ),可以提供超低的 IO 延迟
l 三星在 17 年做了超低延迟的闪存芯⽚,叫 ZNAND flash 。当时的市场需求不⼤,就放弃这个产品。因为 BaM 和 SCADA 的出现,加上英伟达的到处宣传,三星在 25 年⼜重新恢复 ZNAND 的研究。
当然各⽅⾯的消息说,铠侠、镁光、 SK 海⼒⼠都宣称要做 1 亿 IOPS 的 SSD 。
GPU-SSD 直通本⾝的不确定性
25 年算是学术圈和各路⼚商为 BaM 架构疯狂的⼀年,到了 26 年 BaM 架构是否还是⼤家坚定的选择,我觉得还是存在⼀定的不确定性的。
GPU-SSD 直通技术只为英伟达的专业 GPU 卡设计。 BaM ⽬前只能在英伟达有限的⾼ 端 GPU 卡上正常运⾏,理由是英伟达只为这些⾼端 GPU 卡提供了更⼤的 BAR 空间。 BaM 移植到英伟达的低端 GPU 卡或者其他品牌的 GPU 卡是否有难度,需要打个问号。背后的逻辑其实也⽐较好懂,公司的屁股都是歪的,肯定希望所有的新技术都是围绕着⾃⼰的产品做的,这些新技术就会是公司的护城河。所有⼈都会同意 AI 是未来,但是 AI 的未来是不是 GPU ,这点是存疑的。
在我看来,未来可能是 DPU 、 8 NPU 、 XPU 、近存计算这些加速器百花⻬放、百家争鸣的阶段。为未来做准备,我们需要考虑的是加速器-SSD 的直通,⽽不只是 GPU-SSD 的直通。这就带来的⼀个疑问:我们是否需要为每种加速器都设计⼀个 BaM 架构?
其次, GPU-SSD 直通技术和分离式架构不搭边。其实 25 年还有⼀个很⽕的技术,叫 Scale-Up ⽹络,也叫超节点总线互联。其中最有代表性的就是 Compute Express Link ( CXL )【11】、华为的 Unified Bus ( UB )【12】。当然,这⾥我想聊的是在这些技术之上搭建的分离式架构。资源分离( resource disaggregation )是⽬前云⼚商提⾼资源利⽤率的有效⽅案之⼀。 Scale-Up ⽹络把节点间互联的代价降得很低,使得资源分离变得可⾏。
根据这个发展趋势,未来 GPU 会是加速器池, SSD ⼤概率也会变成⼀个存储池,这就跟 BaM 架构产⽣了⽭盾。 BaM 架构是围绕 GPU-SSD 直通的, 但是分离式架构会变成 GPU-NIC-SSD 的形态。同时 BaM 默认是 GPU 独占 SSD ,但是分离式架构需要多个 GPU 和多个 SSD 彼此共享,这就增加了很多设计上的难度。
可能有⼈会反驳:“BaM 是整个内存层次结构中的节点本地缓存。 GPU 节点依然可以通过互联⽹络接⼊存储池,作为内存层次结构的最后⼀层。和存储池相⽐,BaM 能提供更低的延迟和更⾼的吞吐。 ”
我的观点是:在超节点流⾏的当下,如果⽹卡的带宽能够喂饱 GPU 的 PCIe 带宽,同时⽹络延迟远低于 SSD 的 IO 访问延迟,内存层次结构是否需要保留本地 SSD 并维护 BaM ,这点存疑的。
最后, 1 亿 IOPS 的代价⽐较⼤。 1 亿 IOPS 的代价其实可以分两个⽅⾯来看,⼀个是 SSD 的代价,另⼀个是 GPU 的代价。
从 SSD 说起,⽬前企业级 PCIe 5.0 SSD 能提供最多 300 万 IOPS 的性能,但是需要 5 颗 ARM cores 来做固件任务。扩展开来, 1 亿 IOPS 的 SSD 可能需要 160 颗以上的 ARM cores 做固件任务,⽬前来看只有服务器上的 ARM 处理器能勉强满⾜需求,那价格、 功耗、⾯积就基本没边了。 SSD 的板载内存的带宽可能也是⼀⼤挑战。 SSD 的板载内存需要在 DMA 的时候缓存写⼊或者读出的数据,同时执⾏固件任务⽐如 flash translation layer ( FTL )的时候, SSD 的板载内存需要被频繁地访问元数据。这⼀系列原因导致 SSD 的板载内存⾯临特别⼤的带宽压⼒。所以很⾃然的问题是,按照现有的 SSD 架构设计 1 亿 IOPS 的⾼性能 SSD ,是否值得?
回到 GPU, BaM 架构需要消费 GPU 的算⼒来执⾏ I/O任务,包括NVMe队列管理、I/O完成状态的轮询、I/O buffer和data buffer的管理等。尽管BaM没有精确地测量出具体的算力开销,DeepSeek的一份报告给出了网络I/O任务对GPU算力的要求。由于两者都需要GPU承担额外的数据移动与控制开销,我们可以参考这个报告评估BaM对于GPU算力的影响。报告指出,在训练过程中H800 GPU至多有约15%的计算核⼼需要专门⽤来处理 IO 任务【13】。这⾥的问题是,考虑到GPU高昂的价格,占用GPU宝贵的计算核心实现 GPU-SSD 直通,付出这样的代价是否值得?
四、未来:⼀些脑洞和想法
其实围绕这些不确定性,我和实验室的同学们开了不少脑洞。如果对细节特别感兴趣的朋 友,可以随时关注实验室 release 的论⽂和⽂章。这⾥我就简单列举⼏个:
l 过去⼏年,我⼀直想跟学术圈和⼯业界推⼴ SSD-centric 架构,这个架构正好能解决 BaM 的问题。在我看来,SSD 其实是⼀个迷你的计算机⼦系统,固件是⼀个简化的操 作系统,FTL 是简化的⽂件系统或者 KV 引擎, host interface layer ( HIL )和 flash interface layer ( FIL )⾥的队列⾮常类似传统操作系统的块层和 NVMe 驱动层的队列。很⾃然的想法就是让存储软件栈和 SSD 固件合并,这样就能在不额外增加 SSD 控制器负担的前提下,实现完整的存储软件栈到 SSD 的卸载。我⼀直在推进这⽅⾯的研究,感兴趣的朋友可以看这⼏个⼯作【13,14】。这么做对于加速器-SSD 直通的好处是,加速器本⾝只要做到最轻量的存储软件栈集成就能实现 SSD 直通,避免为每个新加速器做繁重的移植。
l 既然 GPU 处理 IO 任务的代价特别⼤,我们能不能换个别的设备帮忙处理⼀下。这⾥⼀ 下⼦就可以脑洞⼤开了,可以是设计某个 ASIC 芯⽚挂在数据传输路径上。这个想法其实⾮常像韩国⾸尔国⽴⼤学 Jaewoo Kim ⽼师团队提出的 IOMMU 加速器,感兴趣的朋友可以看这篇论⽂【15】。另⼀种法⼦是改造⼀下其他设备,⽐如 Smart NIC 或者 DPU ,我这两年有过⼀些类似的想法【17】。
l 既然 SSD 处理海量 IO 任务的代价也⾮常⼤,我们能不能不让 SSD 处理海量 IO 任务。关于这点,我想⽑遂⾃荐我⾃⼰的⼯作【2,16】。核⼼想法是,我把 SSD 控制器和板载内存都扔了,然后把闪存阵列和闪存通道集成到 GPU 卡⾥,让 GPU 替 SSD 执⾏固件任务。当然,刚刚也说了 GPU 处理 IO 任务的代价特别⼤,所以固件任务其实是做了很⼤程度上的简化,使得固件任务能够和 GPU 本⾝的计算任务合并,尽可能开销。后来,韩国⾸尔国⽴⼤学针对 DNN 训练,把我这个⼯作⼜进⾏了魔改,不过整体概念⾮常类似【18】。
l 最后的最后,把 GPU-SSD 直通改造成加速器-NIC-SSD 直通,这可能是拥抱分离式 架构最直接的⽅案之⼀,也是最容易落地的⽅案之⼀。这么设计的收益很明显,我们不需要打造 1 亿 IOPS 的 AI SSD 。加速器需要多少 IO 带宽,让存储池给分配就好, Scale-Up 互联⽹络的带宽也很充裕。同时多加速器之间的数据共享也可以借助 Scale-Up 互联⽹络提供的⼀致性满⾜( CXL 3.0 的特性,虽然还没硬件实物),避免像 BaM ⼀样, SSD 归某个 GPU 私有的限制太多。当然实验室同学在实际部署的时候也遇到了不少问题,这⾥就不⼀⼀展开了,设计细节会陆续 release 。
【作者简介】HPCA名人堂首位90后成员,获得华为奥林帕斯奖、英特尔中国学术英才计划、ACM China SIGCSE新星奖,长期从事存储系统和体系结构研究。
References:
[1] Z. Zhou, S. Yi, and J. Zhang, "Survey on storage-accelerator data movement," CCF Trans. High Perform. Comput., vol. 4, no. 4, pp. 435–447, 2022.
[2] J. Zhang and M. Jung, "ZnG: Architecting GPU multi-processors with new flash for scalable data analysis," in ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA 2020), IEEE, 2020.
[3] X. Pan, E. Li, Q. Li, S. Liang, Y. Shan, K. Zhou, Y. Luo, X. Wang, and J. Zhang, "InstAttention: In-storage attention offloading for cost-effective long-context LLM inference," in 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pp. 1510–1525, IEEE, 2025.
[4] X. Zheng, D. Wei, J. Gao, Y. Song, Z. Mi, and H. Chen, "SolidAttention: Low-latency SSD-based serving on memory-constrained PCs," in USENIX Conference on File and Storage Technologies (FAST), 2026.
[5] S. Bergman, T. Brokhman, T. Cohen, and M. Silberstein, "SPIN: Seamless operating system integration of peer to-peer DMA between SSDs and GPUs," ACM Trans. Comput. Syst. (TOCS), vol. 36, no. 2, pp. 1–26, 2019.
[6] J. Zhang, D. Donofrio, J. Shalf, M. T. Kandemir, and M. Jung, "Nvmmu: A non-volatile memory management unit for heterogeneous GPU-SSD architectures," in 2015 International Conference on Parallel Architecture and Compilation (PACT), pp. 13–24, IEEE, 2015.
[7] S. Qiu, W. Liu, Y. Hu, J. Yan, Z. Shen, X. Yao, R. Chen, G. Zhang, and Y. Zhang, "GeminiFS: A companion file system for GPUs," in the 23rd USENIX Conference on File and Storage Technologies (FAST 25), pp. 221–236. 2025.
[8] S. Li, Y. E. Zhou, Y. Xue, Y. Xu, and J. Huang, "Managing scalable direct storage accesses for GPUs with GoFS," in ACM SIGOPS 31st Symposium on Operating Systems Principles (SOSP), pp. 979–995. 2025.
[9] Z. Qureshi, V. S. Mailthody, I. Gelado, S. Min, A. Masood, J. Park, J. Xiong et al., "BaM: A case for enabling fine grain high throughput GPU-orchestrated access to storage," arXiv preprint arXiv:2203.04910, 2022.
[10] Z. Qureshi, V. S. Mailthody, I. Gelado, S. Min, A. Masood, J. Park, J. Xiong et al., "GPU-initiated on-demand high throughput storage access in the BaM system architecture," in the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, vol. 2, pp. 325–339, 2023.
[11] Y. An, S. Yi, B. Mao, Q. Li, K. Zhou, and N. Xiao, "Xerxes: Extensive exploration of scalable hardware systems with CXL-based simulation framework," in USENIX Conference on File and Storage Technologies (FAST), 2026.
[12] H. Liao, B. Liu, X. Chen, Z. Guo, C. Cheng, J. Wang, X. Chen et al., "UB-Mesh: A hierarchically localized nD FullMesh data center network architecture," IEEE Micro, 2025.
[13] C. Zhao, C. Deng, C. Ruan, D. Dai, H. Gao, J. Li et al., "Insights into DeepSeek-V3: Scaling challenges and reflections on hardware for AI architectures," arXiv preprint arXiv:2505.09343, 2025.
[14] L. Peng, Y. An, Y. Zhou, C. Wang, Q. Li, C. Cheng, and J. Zhang, "ScalaCache: Scalable user-space page cache management with software-hardware coordination," in 2024 USENIX Annual Technical Conference (USENIX ATC 24), pp. 1185–1202, 2024.
[15] S. Yi, X. Pan, Q. Li, Q. Li, C. Wang, B. Mao, M. Jung, and J. Zhang, "ScalaAFA: Constructing user-space all-flash array engine with holistic designs," in 2024 USENIX Annual Technical Conference (USENIX ATC 24), pp. 141–156, 2024.
[16] J. Ahn, D. Kwon, Y. Kim, M. Ajdari, J. Lee, and J. Kim, "DCS: A fast and scalable device-centric server architecture," in the 48th International Symposium on Microarchitecture, pp. 559–571, 2015.
[17] J. Zhang, M. Kwon, H. Kim, H. Kim, and M. Jung, "FlashGPU: Placing new flash next to GPU cores," in the 56th Annual Design Automation Conference, pp. 1–6. 2019.
[18] X. Pan, Y. An, S. Liang, B. Mao, M. Zhang, Q. Li, M. Jung, and J. Zhang, "Flagger: Cooperative acceleration for large-scale cross-silo federated learning aggregation," in 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pp. 915–930. IEEE, 2024.
[19] S. Kim, Y. Jin, G. Sohn, J. Bae, T. J. Ham, and J. W. Lee, "Behemoth: A flash-centric training accelerator for extreme-scale DNNs," in the 19th USENIX Conference on File and Storage Technologies (FAST 21), pp. 371–385, 2021.
[20] C.-H. Chang, J. Han, A. Sivasubramaniam, V. S. Mailthody, Z. Qureshi, and W.-M. Hwu, "GMT: GPU orchestrated memory tiering for the big data era," in the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, vol. 3, pp. 464–478, 2024.
